REST API의 이해와 설계
#3 API 보안
REST API 보안
API 보안에 대해서는 백번,천번을 강조해도 과함이 없다. 근래에 대부분의 서비스 시스템들은 API를 기반으로 통신을 한다.
앱과 서버간의 통신 또는 자바스크립트 웹 클라이언트 와 서버간의 통신등 대부분의 통신이 이 API들을 이용해서 이루어지기 때문에, 한번 보안이 뚫려 버리면 개인 정보가 탈취되는 것 뿐만 아니라 많은 큰 문제를 야기할 수 있다.
REST API 보안 관점
API는 보안 포인트에 따라서 여러가지 보안 관점이 존재하는데, 크게 아래와 같이 5가지 정도로 볼 수 있다.
인증 (Authentication)
인증은 누가 서비스를 사용하는지를 확인하는 절차이다.
쉽게 생각하면 웹 사이트에 사용자 아이디와 비밀 번호를 넣어서, 사용자를 확인하는 과정이 인증이다.
API도 마찬가지로 API를 호출하는 대상 (단말이 되었건, 다른 서버가 되었건, 사용자가 되었건)을 확인하는 절차가 필요하고 이를 API 인증이라고 한다.
인가 (Authorization)
인가는 해당 리소스에 대해서, 사용자가 그 리소스를 사용할 권한이 있는지 체크하는 권한 체크 과정이다.
예를 들어 /users라는 리소스가 있을 때, 일반 사용자 권한으로는 내 사용자 정보만 볼 수 있지만, 관리자 권한으로는 다른 사용자 정보를 볼 수 있는 것과 같은 권한의 차이를 의미한다.
네트워크 레벨 암호화
인증과 인가 과정이 끝나서 API를 호출하게 되면, 네트워크를 통해서 데이터가 왔다갔다 하는데, 해커등이 중간에 이 네트워크 통신을 낚아 채서(감청) 데이터를 볼 수 없게 할 필요가 있다.
이를 네트워크 프로토콜단에서 처리하는 것을 네트워크 레벨의 암호화라고 하는데, HTTP에서의 네트워크 레벨 암호화는 일반적으로 HTTPS 기반의 보안 프로토콜을 사용한다.
메시지 무결성 보장
메시지 무결성이란, 메시지가 중간에 해커와 같은 외부 요인에 의해서 변조가 되지 않게 방지하는 것을 이야기 한다.
무결성을 보장하기 위해서 많이 사용하는 방식은 메시지에 대한 Signature를 생성해서 메시지와 같이 보낸 후에 검증하는 방식으로, 예를 들어 메시지 문자열이 있을 때, 이 문자열에 대한 해쉬코드를 생성해서, 문자열과 함께 보낸 후, 수신쪽에서 받은 문자열과 이 받은 문자열로 생성한 해쉬 코드를 문자열과 함께 온 해쉬코드와 비교하는 방법이 있다. 만약에 문자열이 중간에 변조되었으면, 원래 문자열과 함께 전송된 해쉬코드와 맞지 않기 때문에 메시지가 중간에 변조가되었는지 확인할 수 있다.
메시지의 무결성의 경우, 앞에서 언급한 네트워크 레벨의 암호화를 완벽하게 사용한다면 외부적인 요인(해커)등에 의해서 메시지를 해석 당할 염려가 없기 때문에 사용할 필요가 없다.
메시지 본문 암호화
네트워크 레벨의 암호화를 사용할 수 없거나, 또는 네트워크 레벨의 암호화를 신뢰할 수 없는 상황의 경우 추가적으로 메시지 자체를 암호화 하는 방법을 사용한다. 이는 애플리케이션 단에서 구현하는데, 전체 메시지를 암호화 하는 방법과 특정 필드만 암호화 하는 방법 두가지로 접근할 수 있다.
전체 메시지를 암호화할 경우, 암호화에 소요되는 비용이 클 뿐더라 중간에 API Gateway등을 통해서 메시지를 열어보고 메시지 기반으로 라우팅 변환하는 작업등이 어렵기 때문에 일반적으로 전체를 암호화 하기 보다는 보안이 필요한 특정 필드만 암호화 하는 방법을 사용한다.
그러면 지금부터 각 보안 관점에 대해서 조금 더 구체적으로 살펴보도록 하자.
인증 (Authentication)
API 에 대한 인증은 여러가지 방법이 있으며 각 방식에 따라 보안 수준과 구현 난이도가 다르기 때문에, 각 방식의 장단점을 잘 이해하여 서비스 수준에 맞는 적절한 API 인증 방식을 선택하도록 할 필요가 있다.
API Key 방식
가장 기초적인 방법은 API Key를 이용하는 방법이다. API Key란 특정 사용자만 알 수 있는 일종의 문자열이다. API를 사용하고자 할 때, 개발자는 API 제공사의 포탈 페이등 등에서 API Key를 발급 받고, API를 호출할 때 API Key를 메시지 안에 넣어 호출한다. 서버는 메시지 안에서 API Key를 읽어 이 API가 누가 호출한 API인지를 인증하는 흐름이다.
모든 클라이언트들이 같은 API Key를 공유하기 때문에 한번 API Key가 노출이 되면 전체 API가 뚫려 버리는 문제가 있기 때문에 높은 보안 인증을 요구 하는 경우에는 권장하지 않는다.
API Token 방식
다른 방식으로는 API Token을 발급하는 방식이 있는데, 사용자 ID,PASSWD등으로 사용자를 인증한 후에, 그 사용자가 API 호출에 사용할 기간이 유효한 API Token을 발급해서 API Token으로 사용자를 인증하는 방식이다.
매번 API 호출시 사용자 ID,PASSWD를 보내지 않고, API Token을 사용하는 이유는 사용자 PASSWD는 주기적으로 바뀔 수 있기 때문이고, 매번 네트워크를 통해서 사용자 ID와 PASSWD를 보내는 것은 보안적으로 사용자 계정 정보를 탈취 당할 가능성이 높기 때문에 API Token을 별도로 발급해서 사용하는 것이다.
API Token을 탈취 당하면 API를 호출할 수 는 있지만, 반대로 사용자 ID와 PASSWD는 탈취 당하지 않는다. 사용자PASSWD를 탈취당하면 일반적으로 사용자들은 다른 서비스에도 같은 PASSWD를 사용하는 경우가 많기 때문에 연쇄적으로 다른 서비스에 대해서도 공격을 당할 수 있는 가능성이 높아지기 때문이다. 예를 들어서 매번 호출시마다 사용자 ID,PASSWD를 보내서 페이스북의 계정과 비밀번호를 탈취 당한 경우, 해커가 이 계정과 비밀 번호를 이용해서 GMail이나 트위터와 같은 다른 서비스까지 해킹 할 수 있기 때문에, 이러한 가능성을 최소화하기 위함이다.

흐름을 설명하면 위의 그림과 같다.
1. API Client가 사용자 ID,PASSWD를 보내서 API호출을 위한 API Token을 요청한다.
2. API 인증 서버는 사용자 ID,PASSWD를 가지고, 사용자 정보를 바탕으로 사용자를 인증한다.
3. 인증된 사용자에 대해서 API Token을 발급한다. (유효 기간을 가지고 있다.)
4. API Client는 이 API Token으로 API를 호출한다. API Server는 API Token이 유효한지를 API Token 관리 서버에 문의하고, API Token이 유효하면 API 호출을 받아 들인다.
이 인증 방식에는 여러가지 다양한 변종이 존재하는데
먼저 1단계의 사용자 인증 단계에서는 보안 수준에 따라서 여러가지 방식을 사용할 수 있다.
HTTP Basic Auth
※ 상세 : http://en.wikipedia.org/wiki/Basic_access_authentication
가장 기본적이고 단순한 형태의 인증 방식으로 사용자 ID와 PASSWD를 HTTP Header에 Base64 인코딩 형태로 넣어서 인증을 요청한다.
예를 들어 사용자 ID가 terry이고 PASSWD가 hello world일 때, 다음과 같이 HTTP 헤더에 “terry:hello world”라는 문자열을 Base64 인코딩을해서 “Authorization”이라는 이름의 헤더로 서버에 전송하여 인증을 요청한다.
Authorization: Basic VGVycnk6aGVsbG8gd29ybGQ=
중간에 패킷을 가로채서 이 헤더를 Base64로 디코딩하면 사용자 ID와 PASSWD가 그대로 노출되기 때문에 반드시 HTTPS 프로토콜을 사용해야 한다.
Digest access Authentication
※ 상세 : http://en.wikipedia.org/wiki/Digest_access_authentication
HTTP Basic Auth가 Base64 형태로 PASSWD를 실어서 보내는 단점을 보강하여 나온 인증 프로토콜이 Digest access Authentication 이라는 방법으로, 기본 원리는 클라이언트가 인증을 요청할 때, 클라이언트가 서버로부터 nonce 라는 일종의 난수값을 받은 후에, (서버와 클라이언트는 이 난수 값을 서로 알고 있음), 사용자 ID와 PASSWD를 이 난수값을 이용해서 HASH화하여 서버로 전송하는 방식이다.
이 경우에는 직접 ID와 PASSWD가 평문 형태로 날아가지 않기 때문에, 해커가 중간에 PASSWD를 탈취할 수 없고, 설령 HASH 알고리즘을 알고 있다고 하더라도, HASH된 값에서 반대로 PASSWD를 추출하기가 어렵기 때문에, Basic Auth 방식에 비해서 향상된 보안을 제공한다. 전체적인 흐름을 보자
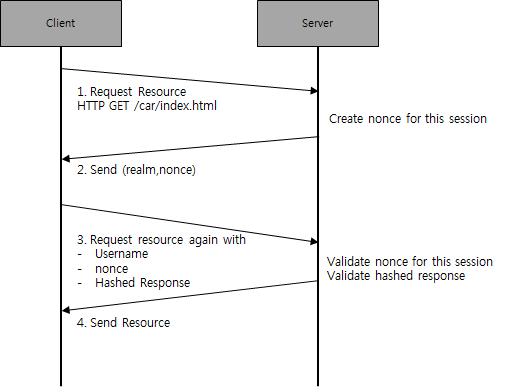
1. 클라이언트가 서버에 특정리소스 /car/index.html 을 요청한다.
2. 서버는 해당 세션에 대한 nonce값을 생성하여 저장한 후에, 클라이언트에 리턴한다. 이때 realm을 같이 리턴하는데, realm은 인증의 범위로, 예를 들어 하나의 웹 서버에 car.war, market.war가 각각 http://myweb/car , http://myweb/market 이라는 URL로 배포가 되었다고 하면, 이 웹사이트는 각각 애플리케이션 car.war와 market.war에 대해서 서로 다른 인증realm을 갖는다.
※ 해당 session에 대해서 nonce 값을 유지 저장해야 하기 때문에, 서버 쪽에서는 상태 유지에 대한 부담이 생긴다. HTTP Session을 사용하거나 또는 서버간에 공유 메모리(memcached나 redis등)을 넣어서 서버간에 상태 정보를 유지할 수 있는 설계가 필요하다.
3. 클라이언트는 앞에서 서버로부터 받은 realm과 nonce값으로 Hash 값을 생성하는데,
HA1 = MD5(사용자이름:realm:비밀번호)
HA2 = MD5(HTTP method:HTTP URL)
response hash = MD5(HA1:nonce:HA2)
를 통해서 response hash 값을 생성한다.
예를 들어서 /car/index.html 페이지를 접근하려고 했다고 하자, 서버에서 nonce값을 dcd98b7102dd2f0e8b11d0f600bfb0c093를 리턴하였고, realm은 car_realm@myweb.com 이라고 하자. 그리고 사용자 이름이 terry, 비밀 번호가 hello world하면
HA1 = MD5(terry:car_realm@myweb.com:hello world)로 7f052c45acf53fa508741fcf68b5c860 값이 생성되고
HA2 = MD5(GET:/car/index.html) 으로 0c9f8cf299f5fc5c38d5a68198f27247 값이 생성된다.
Response Hash는MD5(7f052c45acf53fa508741fcf68b5c860: dcd98b7102dd2f0e8b11d0f600bfb0c093:0c9f8cf299f5fc5c38d5a68198f27247) 로 결과는 95b0497f435dcc9019c335253791762f 된다.
클라이언트는 사용자 이름인 “terry”와 앞서 받은 nonce값인 dcd98b7102dd2f0e8b11d0f600bfb0c093와 계산된 hash값인 95b0497f435dcc9019c335253791762f 값을 서버에게 전송한다.
4. 서버는 먼저 3에서 전달된 nonce값이 이 세션을 위해서 서버에 저장된 nonce 값과 같은지 비교를 한후, 전달된 사용자 이름인 terry와nonce값 그리고 서버에 저장된 사용자 비밀 번호를 이용해서 3번과 같은 방식으로 response hash 값을 계산하여 클라이언트에서 전달된 hash값과 같은지 비교를 하고 같으면 해당 리소스를 (/car/index.html 파일)을 리턴한다.
간단한 기본 메커니즘만 설명한것이며, 사실 digest access authentication은 qop (quality of protection)이라는 레벨에 따라서 여러가지 변종(추가적인 보안)을 지원한다. 언뜻 보면 복잡해서 보안 레벨이 높아보이지만 사실 Hash 알고리즘으로 MD5를 사용하는데, 이 MD5는 보안 레벨이 낮기 때문에 미정부 보안 인증 규격인 FIPS인증 (http://csrc.nist.gov/publications/fips/fips140-2/fips1402annexa.pdf) 에서 인증하고 있지 않다. FIPS 인증에서는 최소한 SHA-1,SHA1-244,SHA1-256 이상의 해쉬 알고리즘을 사용하도록 권장하고 있다.
MD5 해쉬의 경우에는 특히나 Dictionary Attack에 취약한데, Dictionary Attack이란, Hash된 값과 원래 값을 Dictionary (사전) 데이터 베이스로 유지해놓고, Hash 값으로 원본 메시지를 검색하는 방식인데, 실제로 http://en.wikipedia.org/wiki/Digest_access_authentication 설명에서 예제로 든
- HA1 = MD5( “Mufasa:testrealm@host.com:Circle Of Life” ) = 939e7578ed9e3c518a452acee763bce9
의 MD5 해쉬 값인 939e7578ed9e3c518a452acee763bce9 값을 가지고, MD5 Dictionary 사이트인 http://md5.gromweb.com/?md5=939e7578ed9e3c518a452acee763bce9 에서 검색해보면, Hash 값으로 원본 메시지인 Mufasa:testrealm@host.com:Circle Of Life 값이 Decrypt 되는 것을 확인할 수 있다.

그래서 반드시 추가적인 보안 (HTTPS) 로직등을 겸비해서 사용하기를 바라며, 더 높은 보안 레벨이 필요한 경우 다른 인증 메커니즘을 사용하는 것이 좋다.
FIPS 인증 수준의 보안 인증 프로토콜로는 SHA-1 알고리즘을 사용하는 SRP6a 등이 있다. 높은 수준의 보안이 필요할 경우에는 아래 링크를 참고하기 바란다. http://en.wikipedia.org/wiki/Secure_Remote_Password_protocol
클라이언트 인증 추가
추가적인 보안 강화를 위해서 사용자 인증 뿐만 아니라, 클라이언트 인증 방식을 추가할 수 있다. 페이스북의 경우 API Token을 발급 받기 위해서, 사용자 ID,PASSWD 뿐만 아니라 client Id와 Client Secret이라는 것을 같이 입력 받도록 하는데,
Client Id는 특정 앱에 대한 등록 Id이고, Client Secret은 특정 앱에 대한 비밀 번호로 페이스북 개바자 포털에서 앱을 등록하면 앱 별로 발급 되는 일종의 비밀 번호이다.
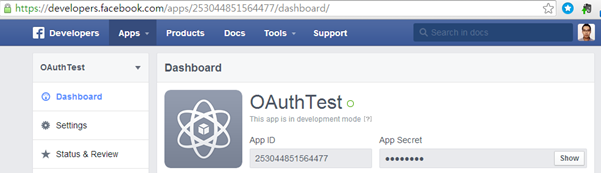
그림. 페이스북 개발자 포탈에서 등록된 client Id(appId)와 client secret(App Secret)을 확인하는 화면
API Token을 발급 받을 때, Client Id와 Client Secret 을 이용하여, 클라이언트 앱을 인증하고 사용자 ID와 PASSWD를 추가로 받아서 사용자를 인증하여 API access Token을 발급한다.
제3자 인증 방식
3자 인증 방식은 페이스북이나 트위터와 같은 API 서비스 제공자들이 파트너 애플리케이션에 많이 적용하는 방법으로 만약 내가 My Server Application라는 서비를 Facebook 계정을 이용하여 인증을 하는 경우이다.
이때 중요한 점은 서비스 My Server Application에 대해서 해당 사용자가 페이스북 사용자임을 인증을 해주지만, 서비스 My Server Application는 사용자의 비밀번호를 받지 않고, 페이스북이 사용자를 인증하고 서비스 My Server Application에게 알려주는 방식이다. 즉 파트너 서비스에 페이스북 사용자의 비밀번호가 노출되지 않는 방식이다.
전체적인 흐름을 보면 다음과 같다.
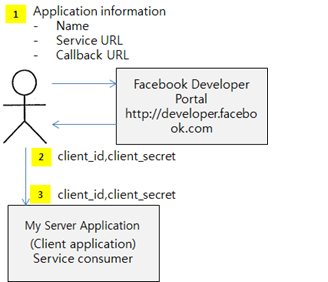
1. 먼저 페이스북의 Developer Portal에 접속을 하여, 페이스북 인증을 사용하고자 하는 애플리케이션 정보를 등록한다. (서비스 명, 서비스 URL,그리고 인증이 성공했을 때 인증 성공 정보를 받을 CallBack URL)
2. 페이스북 Developer Portal은 등록된 정보를 기준으로 해당 애플리케이션에 대한 client_id와 client_secret을 발급한다. 이 값은 앞에서 설명한 클라이언트 인증에 사용된다.
3. 다음으로, 개발하고자 하는 애플리케이션에, 이 client_id와 client_secret등을 넣고, 페이스북 인증 페이지 정보등을 넣어서 애플리케이션을 개발한다.
애플리케이션이 개발되서 실행이 되면, 아래와 같은 흐름에 따라서 사용자 인증을 수행하게 된다.

1. 웹브라우져에서 사용자가 My Server Application 서비스를 접근하려고 요청한다.
2. My Server Application은 사용자가 인증이되어 있지 않기 때문에, 페이스북 로그인 페이지 URL을 HTTP Redirection으로 URL을 브라우져에게 보낸다. 이때 이 URL에 페이스북에 이 로그인 요청이 My Server Application에 대한 사용자 인증 요청임을 알려주기 위해서, client_id등의 추가 정보와 함께, 페이스북의 정보 접근 권한 (사용자 정보, 그룹 정보등)을 scope라는 필드를 통해서 요청한다.
3. 브라우져는 페이스북 로그인 페이지로 이동하여, 2단계에서 받은 추가적인 정보와 함께 로그인을 요청한다.
4. 페이스북은 사용자에게 로그인 창을 보낸다.
5. 사용자는 로그인창에 ID/PASSWD를 입력한다.
6. 페이스북은 사용자를 인증하고, 인증 관련 정보과 함께 브라우져로 전달하면서, My Server Application의 로그인 완료 페이지로 Redirection을 요청한다.
7. My Server Application을 6에서 온 인증 관련 정보를 받는다.
8. My Server Application은 이 정보를 가지고, 페이스북에, 이 사용자가 제대로 인증을 받은 사용자인지를 문의한다.
9. 페이스북은 해당 정보를 보고 사용자가 제대로 인증된 사용자임을 확인해주고, API Access Token을 발급한다.
10. My Server Application은 9에서 받은 API Access Token으로 페이스북 API 서비스에 접근한다.
앞에서 설명했듯이, 이러한 방식은 자사가 아닌 파트너 서비스에게 자사 서비스 사용자의 인증을 거쳐서 API의 접근 권한을 전달하는 방식이다.
이러한 인증 방식의 대표적인 구현체는 OAuth 2.0으로, 이와 같은 제3자 인증뿐만 아니라, 직접 자사의 애플리케이션을 인증하기 위해서, 클라이언트로부터 직접 ID/PASSWD를 입력 받는 등.
클라이언트 타입(웹,서버,모바일 애플리케이션)에 대한 다양한 시나리오를 제공한다.
※ OAuth 2.0에 대한 자세한 설명은 PACKT 출판사의 OAuth 2.0 Identity and Access Management Patterns (by Martin Spasovski) 책을 참고하기를 추천한다.
이러한 3자 인증 방식은 일반적인 서비스에서는 필요하지 않지만, 자사의 API를 파트너등 외부 시스템에 제공하면서 사용자의 ID/PASSWD를 보호하는데는 필요한 서비스이기 때문에, API 를 외부에 적용하는 경우에는 고려를 해야 한다.
IP White List을 이용한 터널링
만약에 API를 호출하는 클라이언트의 API가 일정하다면 사용할 수 있는 손쉬운 방법인데, 서버간의 통신이나 타사 서버와 자사 서버간의 통신 같은 경우에, API 서버는 특정 API URL에 대해서 들어오는 IP 주소를 White List로 유지하는 방법이 있다.
API 서버 앞단에, HAProxy나 Apache와 같은 웹서버를 배치하여서 특정 URL로 들어올 수 있는 IP List를 제한 하거나, 아니면 전체 API가 특정 서버와의 통신에만 사용된다면 아예, 하드웨어 방화벽 자체에 들어올 수 있는 IP List를 제한할 수 있다.
설정만으로 가능한 방법이기 때문에, 서버간의 통신이 있는 경우에는 적용하는 것을 권장한다.
Bi-diretional Certification (Mutual SSL)
가장 높은 수준의 인증 방식을 제공할 수 있는 개념으로, 보통 HTTPS 통신을 사용할 때 서버에 공인 인증서를 놓고 단방향으로 SSL을 제공한다.
반면 Bi-Directional Certification (양방향 인증서 방식) 방식은 클라이언트에도 인증서를 놓고 양방향으로 SSL을 제공하면서, API 호출에 대한 인증을 클라이언트의 인증서를 이용 하는 방식이다.
구현 방법이 가장 복잡한 방식이기는 하지만, 공인 기관에서 발행된 인증서를 사용한다면 API를 호출하는 쪽의 신원을 확실하게 할 수 있고, 메시지까지 암호화되기 때문에, 가장 높은 수준의 인증을 제공한다. 이런 인증 방식은 일반 서비스에서는 사용되지 않으며, 높은 인증 수준을 제공하는 몇몇 서비스나 특정 서버 간 통신에 사용하는 것이 좋다.
권한 인가 (Authorization)
인증이 끝나면 다음 단계는 권한에 대한 인증, 즉 인가 (Authorization) 과정이 필요하다.
사용자가 인증을 받고 로그인을 했다해더라도 해당 API를 호출 할 수 있는 권한이 있는 가를 체크해야 한다.
예를 들어 “일반 사용자 A가 로그인 했을 때, 다른 사용자를 삭제하는 것은 사용자 A가 관리자 권한을 가지고 있고, 이 요청이 웹 관리 콘솔을 통해서 들어온 경우에만 허용한다.” 와 같은 경우이다. 사용자가 인증(Authentication)을 통해서 시스템 내의 사용자 임을 확인 받았지만, API 호출을 하기 위해서 적절한 권한이 있는지를 검증해야 한다.
API 인가 방식
권한 인가(Authorization)방식에는 여러가지 방식이 있는데, 대표적인 방식 몇가지만 보면
가장 일반적인 권한 인증 방식은 사용자의 역할(ROLE)을 기반으로 하는 RBAC (Role Based Access Control)이라는 방식이 있다.
이 방식은 정해진 ROLE에 권한을 연결해놓고, 이 ROLE을 가지고 있는 사용자게 해당 권한을 부여하는 것이다.
예를 들어
- 일반 관리자 – 사용자 관리, 게시물 관리, 회원 가입 승인
- 마스터 관리자 – 까페 게시판 게시판 관리, 메뉴 관리, 사용자 관리, 게시물 관리, 회원 가입 승인
와 같은 권한을 만든후,
Terry에 “마스터 관리자”라는 ROLE을 부여하면, 사용자 Terry는 “까페 게시판 게시판 관리, 메뉴 관리, 사용자 관리, 게시물 관리, 회원 가입 승인” 등의 권한을 가지게 된다.
이렇게 권한 부여의 대상이 되는 사용자나 그룹을 Object라고 하고, 각 개별 권한을 Permission이라고 정의하며, 사용자의 역할을 Role이라고 정의한다. RBAC는 이 Role에 권한을 맵핑 한 다음 Object에 이 Role을 부여 하는 방식으로 많은 권한 인가는 사용자 역할을 기반으로 하기 때문에, 사용하기가 용이하다.

다른 권한 인증 모델로는 ACL (Access Control List)라는 방식이 있다.
RBAC 방식이 권한을 ROLE이라는 중간 매개체를 통해서 사용자에게 부여하는데 반해서, ACL 방식은 사용자(또는 그룹과 같은 권한의 부여 대상) 에게 직접 권한을 부여하는 방식이다.
사용자 Terry 에 직접 “까페 게시판 게시판 관리, 메뉴 관리, 사용자 관리, 게시물 관리, 회원 가입 승인” 권한을 부여 하는 방식이 ACL의 대표적인 예이다.

이러한 API 권한 인가 체크는 인증 (Authentication)이 끝나 후에, 인가에 사용된 api accesstoken을 이용하여 사용자 정보를 조회하고, 사용자 정보에 연관된 권한 정보 (Permission이나 Role정보)를 받아서 이 권한 정보를 기반으로 API 사용 권한을 인가하는 방법을 사용한다. 사용자 정보 조회 “HTTP GET /users/{id}”라는 API 가 있다고 가정하자.
이 API의 권한은 일반 사용자의 경우 자신의 id에 대해서만 사용자 정보 조회가 가능하고, (자신의 정보만), 만약에 관리자의 경우에는 다른 사용자의 id도 조회가 가능하도록 차등하여 권한을 부여할 수 있다.
이러한 권한 검증은 API access token으로 사용자를 찾은 후, 사용자에게 assign 된 ROLE이나 Access Control을 받아서 API 인증을 처리할 수 있다.
API 권한 인가 처리 위치
API에 대한 권한 인가 처리는 여러가지 계층에서 처리할 수 있다.
권한 인가는 API를 호출 하는 쪽인 클라이언트, API를 실행하는 API 서버쪽, 그리고 API 에 대한 중간 길목 역할을 하는 gateway 3군데서 처리할 수 있으며 근래에는 API 서버쪽에서 처리하는 것이 가장 일반적이다.
클라이언트에 의한 API 권한 인가 처리
API를 호출 하는 클라이언트 쪽에서 사용자의 권한에 따라서 API를 호출하는 방식인데, 이 방식의 경우 클라이언트가 신뢰할 수 있는 경우에만 사용할 수 있다.
이 방식은 기존에, 웹 UX 로직이 서버에 배치되어 있는 형태 (Struts나 Spring MVC와 같은 웹 레이어가 있는 경우)에 주로 사용했다.
위의 사용자 API를 예를 들어보면 웹 애플리케이션에서, 사용자 로그인 정보(세션 정보와 같은)를 보고 사용자 권한을 조회한 후에, API를 호출 하는 방식이다.
사용자 세션에, 사용자 ID와 ROLE을 본 후에, ROLE이 일반 사용자일 경우, 세션내의 사용자 ID와 조회하고자 하는 사용자 ID가 일치하는 경우에만 API를 호출 하는 방식이다.
이러한 구조를 사용할 경우 모바일 디바이스 등에 제공하는 API는 사용자 ROLE을 갖는 API와 같이 별도의 권한 인가가 필요 없는 API를 호출 하는 구조를 갖는다.
이 구조를 그림으로 표현해보면 다음과 같다.
Mobile Client는 일반 사용자만 사용한다고 가정하고, 웹 애플리케이션은 일반 사용자와 관리자 모두 사용한다고 했을 때, 일반 사용자의 Mobile Client를 위한 API Server를 별도로 배치하고, 사용자 인증(Authentication)만 되면 모든 API 호출을 허용하도록 한다. Mobile Client에 대한 API는 권한 인증에 대한 개념이 없기 때문에, 인증 처리만 하면 되고, 웹 애플리케이션의 경우에는 일반 사용자냐, 관리자냐에 따라서 권한 인가가 필요하기 때문에 아래 그림과 같이 Web Application에서, API를 호출하기 전에 사용자의 id와 권한에 따라서 API 호출 여부를 결정하는 API 권한 인가(Authorization) 처리를 하게 한다.
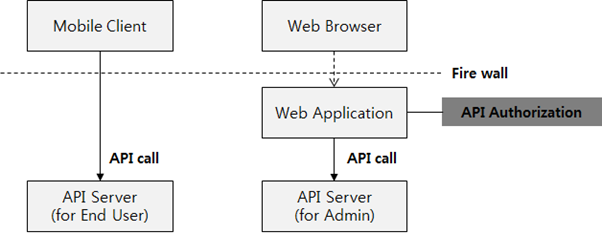
Gateway에 의한 권한 인가 처리
이러한 권한 인가는 모바일 클라이언트, 자바스크립트 기반의 웹 클라이언트등 다양한 클라이언트가 지원됨에 따라 점차 서버쪽으로 이동하기 시작했는데, 특히 자바 스크립트 클라이언트의 경우 클라이언트에서 권한에 대한 인가는 의미가 없기 때문에 어쩔 수 없이 서버 쪽에서 권한 인가 처리를 할 수 밖에 없게 된다. 만약에 자바 스크립트에 권한 인가 로직을 넣을 경우, 자바 스크립트의 경우 브라우져의 디버거등으로 코드 수정이 가능하기 때문에 권한 처리 로직을 위회할 수 도 있고 또한 API 포맷만 안다면 직접 API를 서버로 호출해서 권한 인가 없이 API를 사용할 수 있다.
서버에서 권한을 처리하는 방법은 API 호출의 길목이 되는 gateway나 API 비지니스 로직 두군데서 처리가 가능한데, API gateway에 의한 권한 처리는 구현이 쉽지 않기 때문에,API 서버에서 권한 처리를 하는 것이 일반적이다.
아래 그림은 API gateway에서 권한 인가를 처리하는 방법인데, API 호출이 들어오면, API access Token을 사용자 정보와 권한 정보로 API token management 정보를 이용해서 변환 한 후에, 접근하고자 하는 API에 대해서 권한 인가 처리를 한다.
이는 API 별로 API를 접근하고자 하는데 필요한 권한을 체크해야 하는데, HTTP GET /users/{id}의 API를 예로 들어보면, 이 URL에 대한 API를 호출하기 위해서는 일반 사용자 권한을 가지고 있는 사용자의 경우에는 호출하는 사용자 id와 URL상의 {id}가 일치할 때 호출을 허용하고, 같지 않을 때는 호출을 불허해야 한다.
만약 사용자가 관리자 권한을 가지고 있을 경우에는 호출하는 사용자 id와 URL상의 {id}가 일치하지 않더라도 호출을 허용해야 한다.
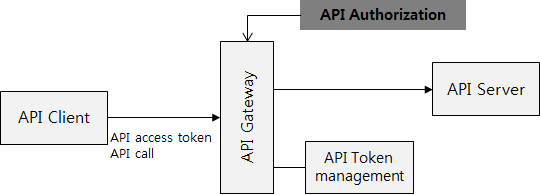
그러나 이러한 api gateway에서의 권한 인가는 쉽지가 않은데, 위의 /users/{id} API의 경우에는 사용자 id가 URL에 들어가 있기 때문에, API access token과 맵핑되는 사용자 ID와 그에 대한 권한을 통해서 API 접근 권한을 통제할 수 있지만, API에 따라서 사용자 id나 권한 인증에 필요한 정보가 HTTP Body에 json 형태나 HTTP Header 등에 들어가 있는 경우, 일일이 메세지 포맷에 따라서 별도의 권한 통제 로직을 gateway 단에서 구현해야 하는 부담이 있고, 권한 통제를 위해서 HTTP 메세지 전체를 일일이 파싱해야 하는 오버로드가 발생하기 때문에, 공통 필드등으로 API 권한 처리를 하지 않는 경우에는 사용하기가 어려운 부분이다.
서버에 의한 API 권한 인가 처리
그래서 가장 일반적이고 보편적인 방법은 API 요청을 처리하는 API 서버의 비지니스 로직단에서 권한 처리를 하는 방식이다.
이 방식은 앞에서 언급한 api gateway 방식과 비교했을때, 각 비지니스 로직에서 API 메세지를 각각 파싱하기 때문에, API 별로 권한 인가 로직을 구현하기가 용이 하다.
이 경우에는 권한 인가에 필요한 필드들을 api gateway에서 변환해서 API 서버로 전달해줌으로써 구현을 간략하게 할 수 있는데,
아래 그림과 같이 API 클라이언트가 api access token을 이용해서 API를 호출했을 경우, api gateway가 이 access token을 권한 인가에 필요한 사용자 id, role등으로 변환해서 API 서버에 전달해주게 되면, 각 비지니스 로직은 API 권한 인가에 필요한 사용자 정보등을 별도로 데이타 베이스를 뒤지지 않고 이 헤더의 내용만을 이용해서 API 권한 인가 처리를 할 수 있게 된다.

네트워크 (전송) 레벨 암호화
가장 기본적이고 필수적인 REST API 보안 방법은 네트워크 전송 프로토콜에서 HTTPS 보안 프로토콜을 사용하는 방법이다. HTTPS 프로토콜만 사용한다 하더라도, 메시지 자체를 암호화 해서 전송하기 때문에, 해킹으로 인한 메시지 누출 위협을 해소화 할 수 있다.
그런데, HTTPS를 사용하더라도, 이러한 메시지를 낚아채거나 변조하는 방법이 있는데, 이러한 해킹 방법을 Man-in-The-Middle-Attack 이라고 한다.
정상적인 HTTPS 통신의 경우, 다음과 같이 서버에서 제공하는 인증서 A를 이용하여 API 클라이언트와 서버 상화간에 암호화된 신뢰된 네트워크 연결을 만든다.

Man in the middle attack의 경우에는 신뢰된 연결을 만들려고 할 때, 해커가 API 클라이언트와 서버 사이에 끼어 들어온다.

다음은 그림과 같이 신뢰된 연결을 만들기 위해서 서버가 인증서 A를 클라이언트에게 내릴 때 해커가 이 인증서가 아닌 인증서 B를 클라이언트에 내리고, 인증서 B를 이용해서 API Client와 Hacker간에 HTTPS SSL 연결을 만든다. 그리고는 서버에게서 받은 인증서 A를 이용해서 해커와 API 서버간의 HTTP SSL 서버를 만든다.
이렇게 되면, 해커는 중간에서 API 클라이언트와 서버 사이에 메시지를 모두 열어 보고 변조도 가능하게 된다.
종종 대기업이나 공공 기관에서 웹브라우져를 사용하다 보면,인증서가 바뀌었다는 메시지를 볼 수 가 있는데 (특히 파이어폭스 브라우져를 사용하면 인증서 변경을 잘 잡아낸다.) 이는 회사의 보안 정책상 HTTPS 프로토콜의 내용을 보고, 이를 감사 하기 위한 목적으로 사용된다.
이런 Man in middle attack을 방지 하는 방법은 여러가지 방식이 있지만, 가장 손쉬운 방법은 공인된 인증서를 사용하고 인증서를 체크하는 것이다.
해커가 인증서를 바꿔 치려면, 인증서를 발급해야 하는데, 공인 인증서는 Verisign과 같은 기간에서 인증서에 대한 공인 인증을 해준다. 즉, 이 인증서를 발급한 사람이 누구이고 이에 대한 신원 정보를 가지고 있다. 이를 공인 인증서라고 하는데, 공인 인증서는 인증 기관의 Signature로 싸인이 되어 있다. (공인 인증기관이 인증했다는 정보가 암호화 되서 들어간다.)
만약 해커가 공인 인증서를 사용하려면 인증 기관에 가서 개인 정보를 등록해야 하기 때문에, 공인 인증서를 사용하기 어렵고 보통 자체 발급한 비공인 인증서를 사용하기 때문에, 이를 이용해서 체크가 가능하고, 특히 인증서안에는 인증서를 발급한 기관의 정보와 인증서에 대한 고유 Serial 번호가 들어가 있기 때문에, 클라이언트에서 이 값을 체크해서 내가 발급하고 인증 받은 공인 인증서인지를 체크하도록 하면 된다.
아래는 자바의 keytool 유틸리티를 이용해서 자체발급한 인증서의 정보를 프린트해본 내용이다.
(※ keytool -printcert -file CERT.RSA)
Owner: CN=Android Debug, O=Android, C=US
Issuer: CN=Android Debug, O=Android, C=US
Serial number: 6b14b6db
Valid from: Mon Nov 19 09:58:00 KST 2012 until: Wed Nov 12 09:58:00 KST 2042
Certificate fingerprints:
MD5: 78:69:7F:D5:BD:D7:B7:47:AD:11:6A:D2:F6:83:D7:CB
SHA1: 44:14:35:A5:C5:28:77:A4:C4:DD:CA:80:26:02:68:A1:84:2E:BD:15
Issuer가 인증서를 발급한 기관의 이름이며, Serial number는 이 인증서에 대한 고유 번호이다. 맨 아래에 있는 fingerprints는 인증서에 대한 해쉬 값으로, 만약에 인증서가 변조되면 이 해쉬값이 달라지기 때문에, 인증서 변조를 확인할 수 있다.
메시지 본문 암호화
다음으로는 간단하게 암호화가 필요한 특정 필드만 애플리케이션단에서 암호화하여 보내는 방법이 있다.
메시지를 암호화 하여 통신하기 위해서는 클라이언트와 서버가 암호화 키를 가져야 하는데, 암호화 키는 크게, 대칭키와, 비대칭키 알고리즘 두가지가 있다.
비대칭키 알고리즘은, 암호화를 시키는 키와, 암호를 푸는 복호화 키가 다른 경우로, 암호화 시키는 키를 보통 Public Key (공개키)라고 하고, 암호화를 푸는 키를 Private Key(비밀키)라고 한다. 이 공개키는 암호화는 할 수 있지만 반대로 암호화된 메시지를 풀 수 가 없기 때문에 누출이 되더라도 안전하다. (해커가 중간에서 공개키를 낚아 챈다고 하더라도, 이 키로는 암호화된 메시지를 복호화 할 수 없다.)
그래서, 처음에 클라이언트가 서버에 인증이 된 경우, 클라이언트에게 이 공개키를 내린 후에, 향후 메시지를 이 공개키를 통해서 암호화를 하게 하면, 이 암호화된 메시지는 비밀키를 가지고 있는 서버만이 풀 수 있어서 안전하게 서버로 메세지를 암호화 해서 보낼 수 있다.
대표적인 비대칭키 알고리즘으로는 RSA등이 있으며, 우리가 익숙한 HTTPS의 경우에도 이 RSA 알고리즘을 사용한다. RSA 알고리즘을 사용하는 비대칭키 암호화 로직과 라이브러리들은 공개된 것이 많으니 참고해서 사용하도록 한다.
비대칭키 알고리즘의 경우 클라이언트에서 서버로 보내는 단방향 메시지에 대해서는 암호화하여 사용할 수 있지만, 반대로 서버에서 클라이언트로 내려오는 응답 메시지등에는 적용하기가 어렵다. 아니면 클라이언트가 서버에 등록될 때, 위와 반대 방법으로 클라이언트에서 비공개키와 공개키 쌍을 생성한 후에, 서버로 공개키를 보내서 향후 서버에서 클라이언트로의 통신을 그 공개키를 사용하도록 해도 된다. 이경우, 클라이언트 ? 서버, 그리고 서버? 클라이언트간의 키 쌍 두개를 관리해야 하기 때문에 복잡할 수 있는데, 이런 경우에는 대칭키 알고리즘을 고려해볼 수 있다.
대칭키 알고리즘은 암호화와 복호화키가 같은 알고리즘이다.
이 경우 API 클라이언트와 서버가 같은 키를 알고 있어야 하는데, 키를 네트워크를 통해서 보낼 경우 중간에 해커에 의해서 낚아채질 염려가 있기 때문에, 양쪽에 안전하게 키를 전송하는 방법이 필요한데, 다음과 같은 방법을 사용할 수 있다.
1. 서버에서 공개키KA1와 비공개키KA2 쌍을 생성한다.
2. 클라이언트에게 공개키 KA1을 네트워크를 통해서 내려보낸다.
3. 클라이언트는 새로운 비공개 대칭키 KB를 생성한후 KA1을 이용해서 암호화하여 서버로 전송한다.
4. 서버는 전송된 암호화 메시지를 KA2로 복화화 하여, 그 안에 있는 비공개키 KB를 꺼낸다.
5. 향후 클라이언트와 서버는 상호 API통신시 비공개 대칭키 KB를 이용하여 암호화와 복호화를 진행한다.
대칭 키도 여러가지 종류가 있는데, 보안과 성능 측면에서 차이가 있다.
http://www.javamex.com/tutorials/cryptography/ciphers.shtml를 참고하면, 대칭키 기반의 암호화 알고리즘 속도를 비교해놓은 것이 있다. 일반적으로 AES256을 사용하면 빠른 암호화 속도와 높은 보안성을 보장받을 수 있다.(아래, 대칭키 기반의 암호화 알고리즘 속도 비교)

메시지 무결성 보장
무결성이란 서버 입장에서 API 호출을 받았을 때 이 호출이 신뢰할 수 있는 호출인지 아닌지를 구별하는 방법이다. 즉 해커가 중간에서 메시지를 가로챈 후, 내용을 변조하여 서버에 보냈을 때, 내용이 변조되었는지 여부를 판단하는 방법인데, 일반적으로 HMAC을 이용한 방식이 널리 사용된다. 어떤 원리로 작동하는지 살펴보도록 하자.
먼저 Rest API를 호출하는 클라이언트와 서버 간에는 대칭키 기반의 암호화 키 ‘Key’를 가지고 있다고 전제하자. 이 키는 클라이언트와 서버 양쪽이 알고 있는 대칭키로, API access Token을 사용할 수 도 있고, 앞의 메시지 본문 암호화에서 나온 방법을 이용해서 서로 대칭키를 교환하여 사용할 수 도 있다..

1. 먼저 클라이언트는 호출하고자 하는 REST API의 URL을 앞에서 정의한 Key를 이용하여 HMAC 알고리즘을 사용하여 Hash 값을 추출한다.
※ 중요: 여기서는 편의상 URL을 가지고 HMAC 해시를 생성하였했는데, 전체 메시지에 대한 무결성을 보장하려면 URL이 아니라 메시지 전문 자체에 대해서 대해 Hash를 추출해야 한다.
2. API를 호출할 때, 메시지(또는 URL)에 추출한 HMAC을 포함해서 호출한다.
3. 서버는 호출된 URL을 보고 HMAC을 제외한 나머지 URL을 미리 정의된 Key를 이용해서, HMAC 알고리즘으로 Hash 값을 추출한다.
4. 서버는 3에서 생성된 HMAC 값과 API 호출 시 같이 넘어온 HMAC 값을 비교해서, 값이 같으면 이 호출을 유효한 호출이라고 판단한다.
만약에 만약 해커가 메시지를 중간에서 가로채어 변조하였했을 경우, 서버에서 Hash를 생성하면 변조된 메시지에 대한 Hash가 생성되기 때문에 클라이언트에서 변조 전에 보낸 Hash 값과 다르게 된다. 이를 통해서 통해 메시지가 변조되었는지 여부를 판단할 수 있다.
그런데, 만약에 만약 메시지를 변경하지 않고 Hacker가 동일한 요청을 계속 보낸다면? 메시지를 변조하지 않았기 때문에 서버는 이를 유효한 호출로 인식할 수 있다. 이를 replay attack이라고 하는데 이를 방지하기 위해서는위해서는 time stamp를 사용하는 방법이 있다.
이 방법은 HMAC을 생성할 때, 메시지를 이용해서만 Hash 값을 생성하는 것이 아니라 timestamp를 포함하여 메시지를 생성하는 것이다.
- HMAC (Key, (메시지 데이터+timestamp) )
그리고 API를 호출할 때, timestamp 값을 같이 실어 보낸다.
http://service.myapi.com/restapiservice?xxxxx&hmac={hashvalue}×tamp={호출시간}
이렇게 하면 서버는 메시지가 호출된 시간을 알 수 있고, 호출된 시간 +-10분(아니면 개발자가 정한 시간폭)만큼의 호출만 정상적인 호출로 인식하고 시간이 지난 호출의 메시지는 비정상적인 호출로 무시하면 된다.
* 참고 : : Hacker가 timestamp URL등 등을 통해서 통해 볼 수 있다고 하더라도, Key 값을 모르기 때문에 timestamp를 변조할 수 없다. timestamp를 변조할 경우에는 원본 Hash가 원본 timestamp로 생성되었기 때문에, timestamp가 변조된 경우 hash 값이 맞지 않게 된다.
HMAC을 구현하는 해시 알고리즘에는 MD5, SHA1등 등이 있는데, 보통 SHA-1 256bit 알고리즘을 널리 사용한다.
HMAC 기반의 REST Hash 구현 방법은
http://www.thebuzzmedia.com/designing-a-secure-rest-api-without-oauth-authentication/
에 설명이 있으니 참고하기 바란다.
또한 HMAC 알고리즘 구현에 대해서는 위키(http://en.wikipedia.org/wiki/HMAC)를 보면 각 프로그래밍 언어별로 예제 링크가 있으므로 참고하기 바란다.
지금까지 간단하게나마 API 보안 방식에 대해서 살펴보았다.보안에 대해서 이야기 하자면 한도 끝도 없겠지만, API보안에서는 최소한 HTTPS를 이용한 네트워크 보안과 함께, API Token등의 인증 방식을 반드시 사용하기를 권장한다.
보안 처리는 하지 않아도, API의 작동이나 사용에는 문제가 없다. 그러나 보안이라는 것은 한번 뚫려버리면 많은 정보가 누출이 되는 것은 물론이고 시스템이 심각한 손상까지 입을 수 있기 때문에, 시간이 걸리더라도 반드시 신경써서 설계 및 구현하는 것을 권장한다.
자바스크립트 클라이언트 지원
근래에 들어서 자바스크립트 기술이 발전하면서 SPA (Sigle Page Application)이 유행하기 시작했는데, SPA란 브라우져에서 페이지간의 이동없이 자바스크립트를 이용해서 동적으로 페이지를 변경할 수 있는 방식이다.
페이지 reloading이 없기 때문에 반응성이 좋아서 많이 사용되는데, SPA 의 경우 서버와의 통신을 자바스크립가 직접 XMLHTTPRequest 객체를 이용해서 API 호출을 바로 하는 형태이다.
이러한 변화는 API 보안 부분에도 새로운 요구사항을 가지고 왔는데, 자바스크립트 클라이언트는 기존의 모바일이나 웹 애플리케이션, 서버등과 다른 기술적인 특성을 가지고 있기 때문이다.
자바스크립트 클라이언트는 코드 자체가 노출된다. 자바스크립트 코드는 브라우져로 로딩되서 수행되기 때문에 사용자 또는 해커가 클라이언트 코드를 볼 수 있다. 그래서 보안 로직등이 들어가 있다고 하더라도 로직 자체는 탈취 당할 수 있다.
아울러 자바스크립트는 실행중에 브라우져의 디버거를 이용해서 변수 값을 보거나 또는 변수값을 변경하거나 비즈니스 로직을 변경하는 등의 행위가 가능하다.
그래서 일반적인 API 보안과는 다른 접근이 필요하다.
Same Origin Policy에 대한 처리
먼저 자바스크립트의 API에 대한 호출은 same origin policy(동일 출처 정책)의 제약을 받는다. Same origin policy란, 자바스크립트와 같이 웹 브라우져에서 동작하는 프로그래밍 언어에서, 웹 브라우져에서 동작하는 프로그램은 해당 프로그램이 로딩된 위치에 있는 리소스만 접근이 가능하다. (http냐 https냐 와 같은 프로토콜과 호출 포트도 정확하게 일치해야 한다.)
아래 그림과 같이 웹사이트 sitea.com에서 자바스크립트를 로딩한 후에, 이 스크립트에서 api.my.com에 있는 API를 XMLHTTPRequest를 통해서 호출하고자 하면, Sane origin policy에 의해서 호출 에러가 난다.

이를 해결하는 방법으로는 인프라 측면에서 Proxy를 사용하는 방법이나 또는 JSONP와 CORS (Cross Origin Resource Sharing)이라는 방법이 있는데, 여기서는 많이 사용되는 CORS에 대해서 소개하고자 한다.
Proxy를 이용하는 방식
Proxy를 이용하는 방식은 간단하다. Same origin policy의 문제는 API 서버와 Javascript가 호스팅 되는 서버의 URL이 다르기 때문에 발생하는 문제인데, 이를 앞단에 Reverse Proxy등을 넣어서, 전체 URL을 같게 만들어 주면 된다.
앞의 상황과 같은 일들이 있다고 가정할 때, sitea.com과 api.my.com 앞에 reverse proxy를 넣고, reverse proxy의 주소를 http://mysite.com 으로 세팅한다.
그리고 mysite.com/javascript로 들어오는 요청은 sitea.com으로 라우팅 하고, mysite.com/의 다른 URL로 들어오는 요청은 api.my.com으로 라우팅한다.

이러한 구조가 되면, javascript 가 로딩된 사이트도 mysite.com이 되고, javascript에서 호출하고자 하는 api URL도 mysite.com이 되기 때문에, Same Origin Policy에 위배되지 않는다.
이 방식은 단순하지만, 자사의 웹사이트를 서비스 하는 경우에만 가능하다. (타사의 사이트를 Reverse Proxy뒤에 놓기는 쉽지 않다.) 그래서 자사의 서비스용 API를 만드는데는 괜찮지만, 파트너사나 일반 개발자에게 자바스크립트용 REST API를 오픈하는 경우에는 적절하지 않다.
특정 사이트에 대한 접근 허용 방식
CORS 방식중,이 방식은 가장 간단하고 쉬운 방식으로 API 서버의 설정에서 모든 소스에서 들어오는 API 호출을 허용하도록 하는 것이다. api.my.com 이라는 API 서비스를 제공할 때, 이 API를 어느 사이트에서라도 로딩된 자바스크립트라도 호출이 가능하게 하는 것이다.
이는 HTTP로 API를 호출하였을 경우 HTTP Response에 응답을 주면서 HTTP Header에 Request Origin (요청을 처리해줄 수 있는 출처)를 명시 하는 방식이다.
api.my.com에서 응답 헤더에
- Access-Control-Allow-Origin: sitea.com
와 같이 명시해주면 sitea.com에 의해서 로딩된 자바스크립트 클라이언트 요청에 대해서만 api.my.com가 요청을 처리해준다.
만약에 다음과 * 로 해주면, request origin에 상관 없이 사이트에서 로딩된 자바스크립트 요청에 대해서 처리를 해준다.
- Access-Control-Allow-Origin: *
Pre-flight를 이용한 세세한 CORS 통제
REST 리소스 (URL)당 섬세한 CORS 통제가 필요한 경우에는 Pre-flight 호출이라는 것을 이용할 수 있다. 이 방식은 REST 리소스를 호출하기 전에, 웹 브라우져가 HTTP OPTIONS 요청을 보내면 해당 REST Resource에 대해서 가능한 CORS 정보를 보내준다. (접근이 허용된 사이트, 접근이 허용된 메서드 등)
웹브라우져에서는 XMLHTTPRequest를 특정 URL로 요청하기 전에 먼저 HTTP Options를 호출한다.
그러면 서버는 해당 URL을 접근할 수 있는 Origin URL과 HTTP Method를 리턴해준다. 이를 pre-flight 호출이라고 하는데, 이 정보를 기반으로 브라우져는 해당 URL에 XMLHTTPRequest를 보낼 수 있다.
아래 그림을 보자, 브라우져는 http://javascriptclient.com에서 로딩된 자바스크립트로 REST 호출을 하려고 한다.
이를 위해서 HTTP OPTION 메서드로 아래 첫번째 화살표와 같이 /myresource URL에 대해서 pre-flight 호출을 보낸다. 여기에는 Origin Site URL과 허가를 요청하는 HTTP 메서드등을 명시한다.
서버는 이 URL에 대한 접근 권한을 리턴하는데, 두번째 화살표와 같이 CORS접근이 가능한 Origin 사이트를 http://javascriptclient.com으로 리턴하고 사용할 수 있는 메서드는 POST,GET,OPTIONS 3개로 정의해서 리턴한다. 그리고 이 pre-flight 호출은 Access-Control-Max-Age에 정의된 1728000초 동안 유효하다. (한번 pre-flight 호출을 하고 나면 이 시간 동안은 다시 pre-flight 호출을 할 필요가 없다.)
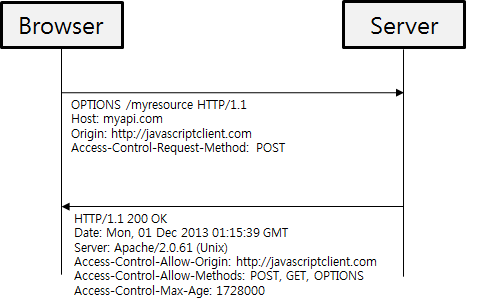
이러한 CORS 설정은 API 호출 코드에서 직접 구현할 수 도 있지만, 그 보다는 앞단에서 로드 밸런서 역할을 하는 HA Proxy나 nginx와 같은 reverse proxy에서 설정을 통해서 간단하게 처리가 가능하다. 만약에 API단에서 구현이 필요하다하더라도 HTTP Header를 직접 건드리지 말고, Spring 등의 프레임웍에서 이미 CORS 구현을 지원하고 있으니 프레임웍을 통해서 간단하게 구현하는 것을 권장한다.
API access Token에 대한 인증 처리
앞서서 언급하였듯이 자바스크립트 클라이언트는 모바일 앱이나, 서버와 같은 다른 API 클라이언트와 비교해서 api access token을 안전하게 저장할 수 있는 방법이 없기 때문에, 이 API access token에 대해서 다른 관리 방식이 필요하다.
몇가지 추가적인 방식을 사용하는데, 내용은 다음과 같다.
api access token을 Secure Cookie를 통해서 주고 받는다.
api access token을 서버에서 발급하여 자바스크립트 클라이언트로 리턴할 때, HTTP body에 리턴하는 것이 아니라 Secure Cookie에 넣어서 리턴한다.
※ Secure Cookie : https://www.owasp.org/index.php/SecureFlag
Secure Cookie는 일반 HTTP 프로토콜을 통해서는 전송이 불가능하고 항상 HTTPS를 통해서만 전송이 가능하다. 같은 API 서버로도 일반 HTTP 호출을 할 경우 api access token이 Cookie를 통해서 전달되지 않기 때문에, 네트워크를 통해서 access token을 탈취하는 것은 불가능하다.
여기에 HTTP_ONLY라는 옵션을 쿠키에 추가하는데, 이 옵션을 적용하게 되면, Cookie를 자바스크립트를 통해서 읽거나 조작할 수 없다. 단지 브라우져가 서버로 요청을 보낼 때, 브라우져에 의해서 자동으로 Cookie가 전송된다.
※ HTTP ONLY 옵션 https://www.owasp.org/index.php/HttpOnly#What_is_HttpOnly.3F
이 두 가지 방법을 쓰면 최소한 자바스크립트 소스코드 분석이나 네트워크 프로토콜 감청을 통한 api access token을 방어할 수 있다
api access token은 해당 세션에서만 유효하도록 한다.
여기에 몇 가지 추가적인 방어 기재를 추가하도록 하는데, 마치 HTTP Session과 같이 특정 IP와 시간내에서만 api access token이 유효하도록 하는 방식이다.
Access token을 발급할 때, access token을 요청한 클라이언트의 IP와 클라이언트의 Origin 을 같이 저장해놓고, 발급할때 유효시간(Expire time)을 정해놓는다. (20 분 등으로).
다음 access token을 이용해서 API가 호출 될 때 마다 IP와 Origin을 확인하고, acess token이 유효시간 (Expire time)시간 내면 이 유효시간을 다시 연장해준다.(+20분을 다시 추가해준다.) 만약에 브라우져에서 일정 시간동안 (20분) API를 호출하지 않았으면 API access token은 폐기되고 다시 access token을 발급 받도록 한다.
이 두 가지 흐름을 도식화해 보면 다음 그림과 같다.

모든 통신을 HTTPS를 이용한다.
1. 자바스크립트 클라이언트가 user id와 password를 보내서 사용자 인증과 함께, API access token을 요청한다. HTTPS를 사용한다하더라도 Man in middle attack에 의해서 password가 노출 될 수 있기 때문에, 앞에서 언급한 Digest access Authentication 등의 인증 메커니즘을 활용하여 가급적이면 password를 직접 보내지 않고 인증을 하는 것이 좋다.
2. 서버에서 사용자 인증이 끝나면 api access token을 발급하고 이를 내부 token store에 저장한다. (앞에서 설명한 origin url, ip, expire time등을 저장한다.). 이 필드들은 웹 자바스크립트를 위한 필드로 설명을 위해서 이 필들만 그림에 정의했지만, 실제 시스템 디자인은 웹 클라이언트용과 일반 서버/모바일 앱등을 위한 api access token 정보도 같이 저장해서 두가지 타입을 access token에 대해서 지원하도록 하는 것이 좋다.
3. 생성된 토큰은 Secure Cookie와 HTTP Only 옵션을 통해서 브라우져에게로 전달된다.
4. 브라우져의 자바스크립트 클라이언트에서는 API를 호출할 때 이 api access token이 secure cookie를 통해서 자동으로 서버에 전송되고, 서버는 이 api access token을 통해서 접근 인증 처리를 하고 api server로 요청을 전달하여 처리하도록 한다.
지금까지 간략하게 나마 REST의 개념에서부터 설계 방식 그리고 보안 측면에 대해서 알아보았다.
적절한 표준이나 가이드가 적은 사항이기 때문에 무엇이 딱 맞다고 말할 수 는 없기 때문에 더더욱 설계등이 어려울 수 있으니, 많은 자료들을 참고해보기 바란다.
특히 아무리 좋은 표준이 있다하더라도 팀이 이를 이해하고 사용하지 못하면 표준은 그냥 문서 덩어리일 뿐이다. 표준과 가이드 정립뿐만 아니라 팀에 대한 교육과 표준 준수에 대한 감사 활동등도 고려 해야 한다.
그리고 항상 강조하지만 보안에 대한 부분은 귀찮더라도 항상 빼먹지 말고 구현하도록 하자.

{kind=link}